Version imprimable multipages. Cliquer ici pour imprimer.
Articles
- Le Pont entre le Métier et l'IT
- Ce qu'on peut faire avec des formats de texte brut
- Concepts de rôles dans l’EAM
- Once-Only dans la documentation
- Différentes normes de modélisation de flux de données
- Les portfolios dans l'EAM, faites visible avec le principe ETS
- Principe ETS dans le contexte de l'EAM
Le Pont entre le Métier et l'IT
Architecture des Systèmes d’Information – Le Pont entre le Métier et l’IT
L’Architecture des Systèmes d’Information (ASI) constitue le lien central entre les besoins métier et leur mise en œuvre technologique. Elle traduit les exigences fonctionnelles issues de l’architecture métier en systèmes d’information concrets, tout en garantissant leur exploitation efficace sur l’infrastructure informatique.
Dans le contexte de la Gestion de l’Architecture d’Entreprise (EAM), elle joue un rôle clé : elle relie les processus métier, les données et les applications pour former une vue d’ensemble cohérente du paysage IT.
flowchart TD id1(Architecture Métier) <--Quoi ? Comment ?--> id2(Architecture des Systèmes d'Information) <--Avec quoi ?--> id3(Architecture Technique) style id1 fill:#ffffee,stroke:#eeeeee,stroke-width:2px style id2 fill:#00ffff,stroke:#000000,stroke-width:2px style id3 fill:#eeffee,stroke:#eeeeee,stroke-width:2px
De quoi s’agit-il exactement ?
L’Architecture des Systèmes d’Information décrit la structure, les relations et les interactions des systèmes d’information au sein d’une entreprise.
Elle répond à des questions centrales telles que :
- Quelles applications soutiennent quels processus métier ?
- Où sont traitées quelles données ?
- Comment les systèmes interagissent-ils entre eux ?
- Quelles dépendances existent ?
L’EAM fournit le cadre méthodologique nécessaire : il permet une vision holistique du métier et de l’IT pour maîtriser la complexité et prendre des décisions éclairées.
Objectifs de l’Architecture des Systèmes d’Information
- Créer de la transparence sur le paysage IT
- Assurer l’alignement entre le métier et l’IT
- Réduire les redondances et la complexité
- Fournir une base pour la planification stratégique de l’IT
Un problème central pour de nombreuses organisations est un paysage système hétérogène, fruit d’une évolution historique, caractérisé par des fonctions redondantes et des interfaces ingérables.
Comment subdiviser l’ASI ?
L’Architecture des Systèmes d’Information peut être divisée en plusieurs sous-domaines étroitement liés :
flowchart LR A(Données / Informations) --> B(Applications) B --> C(Intégration) C --> A
Données/Informations
L’architecture des données décrit les structures de données fonctionnelles et techniques d’une entreprise.
Aspects centraux :
- Objets métier (par ex. client, commande)
- Modèles de données et flux de données
- Qualité des données et responsabilité
- Protection des données et besoins de sécurité
Les données sont le fondement des systèmes d’information – sans une base de données cohérente, aucune architecture stable n’est possible.
Objectif : « Single Source of Truth » (Source unique de vérité) et évitement des redondances
Applications
L’architecture applicative décrit l’ensemble des systèmes d’information utilisés et leur affectation fonctionnelle.
Éléments typiques :
- Applications métier (par ex. ERP, CRM)
- Services / Microservices
- Systèmes legacy (anciens systèmes)
- Paysage applicatif
Un objectif majeur est la maîtrise de la diversité des systèmes, car un trop grand nombre d’applications aux fonctions similaires entraîne une complexité et des coûts croissants.
Objectif : Consolidation et responsabilités claires
Intégration
L’architecture d’intégration décrit comment les applications communiquent entre elles.
flowchart TD A(Système A) -->|API| B(Couche d'Intégration) B -->|Événement| C(Système B) B -->|Batch| D(Système C)
Formes d’intégration typiques :
- APIs (REST, GraphQL)
- Messagerie / Événements
- Traitement ETL / Batch
- Middleware / ESB
L’intégration est l’un des aspects les plus critiques, car c’est souvent là que se crée la plus grande complexité (prolifération des interfaces).
Objectif : Couplage lâche et interfaces standardisées
Principes d’Architecture et Gouvernance
En pratique, l’Architecture des Systèmes d’Information ne peut être pilotée sans garde-fous clairs.
Principes typiques :
- Standardisation avant personnalisation
- Réutilisation avant nouveau développement
- API-First / Orientation services
- Compatibilité Cloud (Cloud-readiness)
Éléments de gouvernance :
- Revues d’architecture
- Architectures cibles et feuilles de route
- Standards technologiques
L’EAM veille à ce que ces principes soient systématiquement appliqués et contrôlés.
Comment assurer le lien avec le Métier et l’Infrastructure IT ?
L’Architecture des Systèmes d’Information agit dans deux directions :
1. Lien avec le Métier
flowchart TD A(Processus Métier) --> B(Système d'Information) B --> C(Objets de Données)
- Les processus métier définissent les besoins
- Les systèmes d’information les mettent en œuvre
- Les données constituent la base fonctionnelle
Cela permet par exemple d’analyser :
« Quels systèmes soutiennent quel processus ? »
2. Lien avec l’Infrastructure IT
flowchart TD A(Système d'Information) --> B(Plateforme) B --> C(Infrastructure)
- Les applications s’exécutent sur des plateformes
- Les plateformes utilisent l’infrastructure (Cloud, réseau, matériel)
- L’architecture technique assure l’exploitation
Mécanismes centraux pour l’alignement
- Transparence par la visualisation (par ex. plans d’urbanisation)
- Liaison des objets métier et IT
- Architecture cible et feuilles de route
- Analyse continue des dépendances
L’EAM permet ici une vue intégrée de toutes les dimensions de l’architecture et rend les relations visibles.
Conclusion
L’Architecture des Systèmes d’Information est bien plus qu’une discipline technique – c’est l’instrument de pilotage central du paysage IT.
Elle :
- Relie le métier et l’IT
- Crée de la transparence et des bases de décision
- Réduit la complexité
- Permet une évolution stratégique
Sans une architecture des systèmes d’information claire, on risque :
- Une croissance incontrôlée du paysage IT
- Une augmentation des coûts et des risques
- Une absence de pilotage stratégique
Avec une ASI établie, en revanche, se crée un pont viable entre la stratégie métier et la mise en œuvre technologique – et ainsi la base d’une transformation numérique réussie.
Ce qu'on peut faire avec des formats de texte brut
Introduction au monde du texte brut
Les contenus numériques sont aujourd’hui créés sous les formes les plus variées : sites web, documentations, présentations ou diagrammes techniques. Traditionnellement, de tels contenus sont souvent créés avec des outils graphiques – tels que Word, PowerPoint ou des logiciels de dessin. Ces outils sont intuitifs mais présentent un inconvénient majeur : les contenus sont généralement stockés dans des formats de fichier propriétaires et sont difficiles à automatiser, à versionner ou à traiter ultérieurement.
Une alternative à cela est les formats en texte brut (Plain Text). Dans ce cas, les contenus ne sont pas décrits visuellement mais via une syntaxe simple, basée sur le texte. Ces fichiers peuvent être édités avec n’importe quel éditeur de texte, facilement versionnés et traités automatiquement.
C’est pourquoi, particulièrement dans le développement logiciel, les environnements DevOps et les processus de documentation modernes, une approche s’est imposée, souvent appelée « Documentation as Code » : les contenus sont traités comme du code source – écrits en texte brut, versionnés dans Git et publiés automatiquement.
Que sont exactement les formats en texte brut ?
Les formats en texte brut sont des formats de fichier dont le contenu consiste en un texte normalement lisible. Ils ne nécessitent aucun logiciel spécifique pour être lus et peuvent être ouverts avec n’importe quel éditeur simple.
Les caractéristiques typiques des formats en texte brut sont :
- Lisibilité humaine – même sans logiciel spécifique
- Structure simple grâce à une syntaxe de balisage légère
- Contrôle de version avec des systèmes comme Git
- Automatisabilité via des pipelines de build
- Portabilité à travers différents systèmes
Un exemple est un simple fichier Markdown :
# Titre
Ceci est un paragraphe.
- Point 1
- Point 2
Le texte reste lisible même s'il n'a pas encore été rendu.
Cette propriété distingue fondamentalement les formats en texte brut de formats comme .docx, .pptx ou .vsdx, qui contiennent en interne des structures XML complexes et ne peuvent être édités de manière significative qu’avec un logiciel spécifique.
Quels formats existent ?
Les formats en texte brut peuvent être grossièrement divisés en deux catégories :
- Formats pour structurer le texte
- Formats pour décrire des visualisations
Les deux suivent le même principe : les contenus sont décrits via une syntaxe simple puis automatiquement rendus.
Formats pour le traitement de texte
Markdown
Markdown est probablement le format en texte brut le plus répandu. Il a été développé pour structurer le texte aussi simplement que possible sans compromettre sa lisibilité.
Les cas d’utilisation typiques incluent :
- Les fichiers README
- La documentation technique
- Les sites web
- Les bases de connaissances
Markdown utilise une syntaxe très simple :
# Titre
## Sous-titre
**Gras**
*italique*
- Liste
- Liste
La force de Markdown réside dans sa simplicité et son large soutien. Des plateformes comme GitHub, GitLab ou de nombreux systèmes CMS prennent directement en charge le Markdown.
L’inconvénient : la fonctionnalité est volontairement limitée. Des structures de documents plus complexes sont plus difficiles à mettre en œuvre avec.
AsciiDoc
AsciiDoc est un format de texte nettement plus puissant que Markdown. Il s’adresse principalement à la documentation technique et aux contenus volumineux.
Par rapport à Markdown, AsciiDoc offre notamment :
- Des structures de documents complexes
- Des tables des matières
- Des références
- Des tableaux
- Des variables et attributs
- Des fonctions extensibles
Exemple :
= Titre du document
Auteur
:toc:
== Chapitre
Un paragraphe.
=== Sous-chapitre
* Liste
* Liste
AsciiDoc est particulièrement adapté pour :
- La documentation technique extensive
- Les manuels
- Les livres
- La documentation d’architecture
Surtout en combinaison avec des outils comme Antora ou Asciidoctor, il permet de générer des portails de documentation très professionnels.
Autres formats connus
Outre Markdown et AsciiDoc, il existe d’autres langages de balisage basés sur le texte :
reStructuredText (reST)
Fréquemment utilisé dans l’écosystème Python, par exemple pour la documentation avec Sphinx.
Org Mode
Un format très puissant issu de l’environnement Emacs, qui combine notes, gestion des tâches et documentation.
LaTeX
Un système de composition à orientation scientifique, particulièrement utilisé pour les contenus mathématiques et les publications scientifiques.
Textile
Un ancien format de balisage qui était auparavant utilisé dans de nombreux wikis.
Formats pour la visualisation
Outre le texte, les diagrammes et visualisations peuvent également être décrits en texte brut.
Ici, on ne dessine pas, mais on décrit la structure d’un diagramme de manière textuelle.
Mermaid
Mermaid est un langage largement répandu pour créer des diagrammes en texte brut. Il est désormais directement pris en charge par de nombreuses plateformes, dont GitHub, GitLab et de nombreux systèmes de documentation.
Un exemple simple :
graph TD
A[Démarrage] --> B{Décision}
B -->|Oui| C[Action]
B -->|Non| D[Fin]
Cela donne :
graph TD
A[Démarrage] --> B{Décision}
B -->|Oui| C[Action]
B -->|Non| D[Fin]
Mermaid prend en charge, entre autres :
- Les organigrammes (Flowcharts)
- Les diagrammes de séquence
- Les diagrammes de Gantt
- Les diagrammes d’état
- Les diagrammes ER (Entité-Relation)
Le grand avantage de Mermaid est sa syntaxe simple et son intégration large dans les plateformes de documentation modernes.
PlantUML
PlantUML est un langage puissant pour décrire des diagrammes UML et de nombreux autres types de diagrammes.
Exemple d’un diagramme de séquence :
@startuml
Alice -> Bob: Requête
Bob --> Alice: Réponse
@enduml
Le résultat:

PlantUML prend en charge :
- Les diagrammes UML
- Les diagrammes de séquence
- Les diagrammes de composants
- Les diagrammes de déploiement
- Les modèles C4
- Les diagrammes d’architecture
PlantUML est particulièrement populaire dans le contexte de l’architecture et de la conception logicielle.
Autres formats connus
Outre Mermaid et PlantUML, il existe d’autres langages de visualisation basés sur le texte :
Graphviz / DOT
L’un des plus anciens langages de description de diagrammes pour les graphes.
D2
Un langage de diagramme moderne axé sur une lisibilité simple.
Structurizr DSL
Un langage spécifiquement conçu pour décrire des diagrammes d’architecture selon le modèle C4.
TikZ
Un langage de diagramme très puissant issu du monde LaTeX.
Possibilités d’application
Les formats en texte brut sont extrêmement polyvalents et peuvent être utilisés dans de nombreux domaines.
Notes
De nombreux systèmes de prise de notes modernes sont basés sur Markdown ou des formats similaires. Les exemples incluent les systèmes de connaissances, les wikis personnels ou les notes structurées.
L’avantage : les notes restent lisibles à long terme et indépendantes d’un logiciel spécifique.
Sites web
De nombreux sites web modernes sont générés à partir de formats en texte brut. Les générateurs de sites statiques transforment automatiquement les fichiers Markdown ou AsciiDoc en pages HTML.
Les outils connus incluent :
- Hugo
- Jekyll
- MkDocs
- Antora
Ce principe est fréquemment utilisé pour les sites web de documentation et les blogs.
Documents
Les documents classiques peuvent également être générés à partir de texte brut :
- Word
- HTML
- Présentations
Des outils comme Pandoc permettent la conversion entre de nombreux formats.
Documentations
La documentation technique profite particulièrement des formats en texte brut.
Ils permettent :
- La gestion de version
- La collaboration via Git
- Des builds automatiques
- Des portails de documentation structurés
Cette approche est souvent appelée Docs-as-Code.
Livres / eBooks
De nombreux livres sont aujourd’hui générés à partir de sources en texte brut. Le même contenu peut ainsi être transformé en différents formats de sortie :
- EPUB
- HTML
Cette approche est très répandue, notamment dans le domaine technique.
Présentations
Les présentations peuvent également être entièrement générées à partir de formats en texte brut aujourd’hui. Au lieu de concevoir directement les diapositives dans des programmes comme PowerPoint ou Keynote, le contenu est d’abord écrit dans un langage de description basé sur le texte, puis automatiquement converti en présentation.
Un exemple simple en Markdown pourrait ressembler à ceci :
# Titre de la présentation
---
## Problématique
- Point 1
- Point 2
---
## Solution
Une approche structurée.
Des frameworks de présentation spécialisés interprètent cette structure et génèrent des diapositives finies.
Les outils typiques incluent :
- Reveal.js – un framework de présentation HTML très répandu, souvent combiné avec Markdown
- Marp – un système de présentation basé sur Markdown, axé sur la création simple et l’export vers PDF ou PowerPoint
- Slidev – un framework de présentation moderne pour les développeurs, basé sur Markdown et Vue.js
- Pandoc – peut convertir Markdown ou AsciiDoc en formats de présentation comme Reveal.js ou Beamer
Un avantage de cette approche est que les présentations peuvent être traitées de la même manière que le code source ou la documentation :
- Les contenus sont versionnables
- Les changements sont traçables
- Les présentations peuvent être générées automatiquement
- Les contenus peuvent être facilement réutilisés
Cette approche est de plus en plus utilisée dans les environnements techniques, par exemple pour :
- Les présentations d’architecture
- Les formations techniques
- Les conférences
- Les présentations de projets
Comme les présentations sont basées sur du texte brut, elles peuvent également être facilement combinées avec d’autres artefacts – par exemple avec des diagrammes générés automatiquement à partir de PlantUML ou Mermaid.
Images
Les images et les diagrammes peuvent également être générés à partir de texte brut, par exemple :
- Diagrammes d’architecture
- Diagrammes de processus
- Diagrammes UML
L’avantage : les modifications peuvent être facilement apportées dans le texte et versionnées.
Outils utiles
Le travail avec les formats en texte brut est soutenu par une multitude d’outils.
Éditeurs de texte
En principe, un simple éditeur suffit. Cependant, les éditeurs spécialisés avec coloration syntaxique et aperçu sont particulièrement confortables.
Les exemples populaires incluent :
- Visual Studio Code
- Obsidian
- Typora
- Sublime Text
Beaucoup de ces outils prennent en charge des plugins pour Markdown, AsciiDoc, Mermaid ou PlantUML.
Convertisseurs
Les convertisseurs permettent la transformation entre différents formats de documents.
Un outil particulièrement puissant est Pandoc, qui peut convertir des centaines de formats les uns dans les autres.
Les conversions typiques incluent :
- Markdown → PDF
- Markdown → Word
- AsciiDoc → HTML
- Markdown → Présentation
Gestion de version
Un grand avantage des formats en texte brut est leur intégration avec les systèmes de gestion de version.
Avec des outils comme Git, les changements peuvent être :
- Traçables
- Comparés
- Édités en collaboration
- Publiés automatiquement
C’est un avantage majeur pour les équipes de documentation par rapport aux documents Office classiques.
Conclusion
Les formats en texte brut offrent une base flexible et pérenne pour la création de contenus numériques. Ils permettent de structurer facilement les textes, les documentations et les diagrammes et de les traiter automatiquement.
Grâce à leur lisibilité, leur ouverture et leur bonne capacité d’intégration, ils s’inscrivent parfaitement dans les processus de développement et de documentation modernes.
Quiconque souhaite rendre les contenus maintenables, versionnables et automatisables à long terme trouvera dans les formats en texte brut une alternative puissante aux outils Office classiques.
Concepts de rôles dans l’EAM
Concepts de Rôles dans l’EAM
Pourquoi des Rôles dans l’EAM ?
La Gestion de l’Architecture d’Entreprise (EAM) évolue dans un champ de tensions entre la stratégie, l’organisation, les systèmes informatiques et les processus opérationnels. Sans rôles clairement définis, il existe un risque que le travail d’architecture reste purement documentaire ou soit mené de manière non coordonnée par différentes parties.
Les rôles dans l’EAM remplissent donc plusieurs fonctions centrales :
1. Clarifier les responsabilités
Les décisions d’architecture concernent de nombreux domaines de l’entreprise. Les rôles assurent qu’il est clair qui prépare, prend ou assume la responsabilité des décisions.
2. Structurer les perspectives
L’EAM examine les organisations sous différents angles (Business, Données, Applications, Technologie). Les rôles aident à ancrer organisationnellement ces perspectives.
3. Permettre la communication
L’architecture est un espace de traduction entre le métier et l’IT. Les rôles définissent qui parle quel langage et représente quels intérêts.
4. Assurer la gouvernance
Les directives d’architecture ne prennent effet que si quelqu’un est responsable de leur mise en œuvre – par exemple, via des comités d’architecture ou des processus de revue.
En bref :
Les rôles constituent le fondement organisationnel pour que l’architecture ne soit pas seulement modélisée, mais aussi vécue et pilotée.
Comment les Cadres de Référence Connus Abordent-ils Cela ?
TOGAF
Le cadre TOGAF définit une série de rôles autour du travail d’architecture, en particulier dans le contexte de la Méthode de Développement de l’Architecture (ADM).
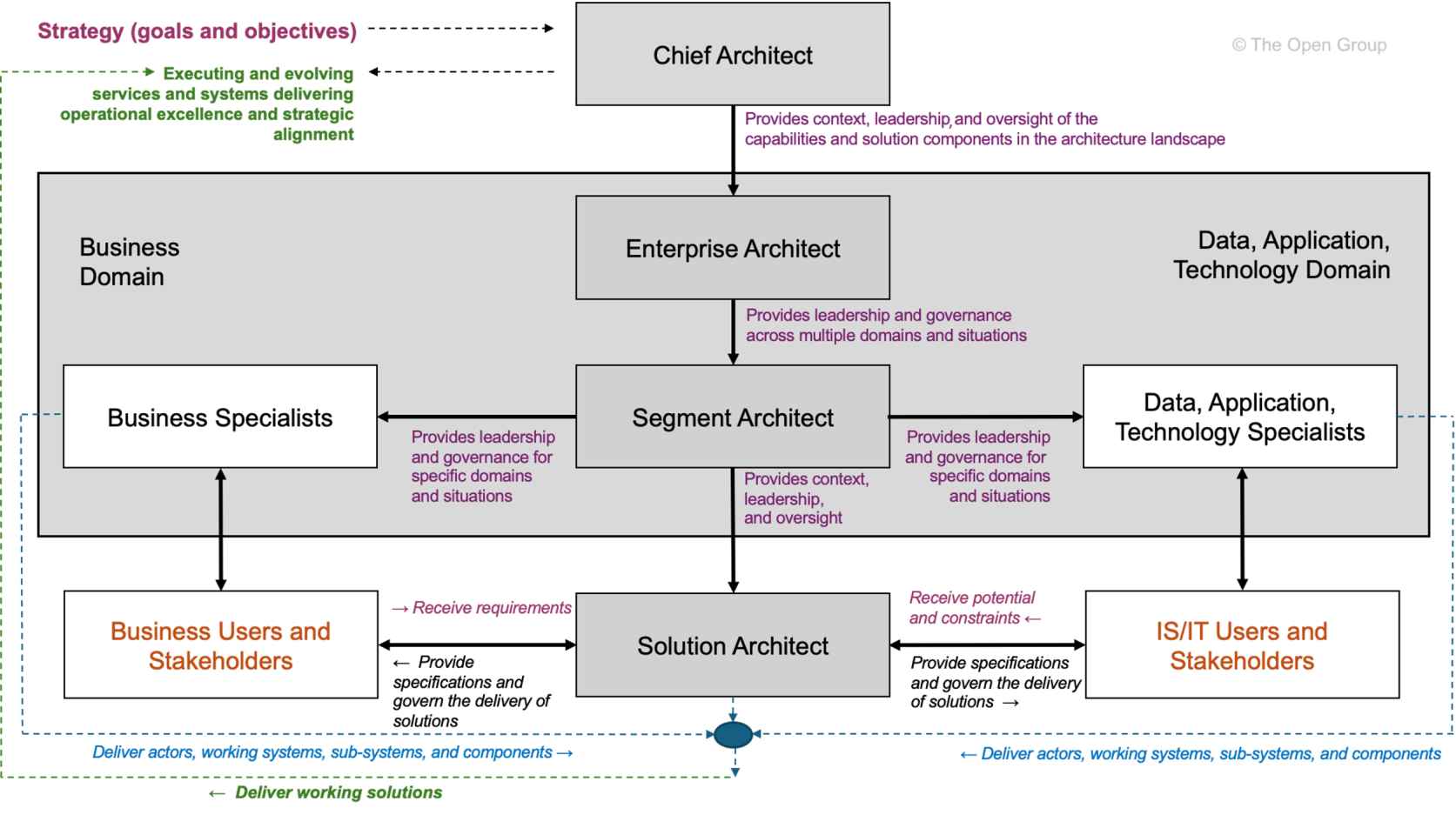 Image de TOGAF Architecture Roles and Skills (Compte utilisateur nécéssaire).
Image de TOGAF Architecture Roles and Skills (Compte utilisateur nécéssaire).
Les rôles architect de TOGAF :
-
Enterprise Architect – Responsabilité globale de l’architecture de l’entreprise
-
Segment Architect – Responsabilité de domaines d’architecture spécifiques (Business, Données, Application, Technologie)
-
Solution Architect – Architecture d’un projet ou d’un système concret
-
Chief Architect – Organe de gouvernance et de décision pour les questions d’architecture
TOGAF considère les rôles principalement sous une perspective de gouvernance et de processus.
Ils sont étroitement liés aux phases de l’ADM et à la gouvernance de l’architecture.
Cependant, les rôles sont délibérément formulés de manière générique et doivent être adaptés par chaque organisation à sa propre structure.
Cadre Zachman
Le cadre Zachman adopte une approche différente. Il ne définit aucun rôle explicite, mais structure plutôt les artefacts d’architecture selon deux dimensions :

Image de About the Zachman Framework.
-
Questions (Quoi, Comment, Où, Qui, Quand, Pourquoi)
-
Perspectives (Planificateur, Propriétaire, Concepteur, Constructeur, Sous-traitant, Système en Fonctionnement)
Les lignes du cadre peuvent cependant être interprétées comme des perspectives de rôles implicites :
| Perspective | Rôle Typique |
|---|---|
| Planificateur | Stratégie / Direction Générale |
| Propriétaire | Responsables Métier |
| Concepteur | Enterprise ou Solution Architect |
| Constructeur | Développeur / Mise en œuvre |
| Sous-traitant | Spécialistes techniques |
La contribution du cadre Zachman réside moins dans des intitulés de rôles concrets que dans le constat :
L’architecture émerge de différentes perspectives et questionnements.
Ainsi, Zachman fournit une bonne base pour dériver systématiquement les rôles des questions fondamentales de l’architecture.
Rôles par Rapport au Principe EVA
Le principe EVA (Entrée – Traitement – Sortie) peut être utilisé comme une structure de pensée simple pour organiser les responsabilités dans le contexte de l’architecture.
Transposées aux questions d’architecture, six perspectives de base peuvent être distinguées :
-
Quoi – Objets et informations
-
Comment – Processus et fonctions
-
Avec Quoi – Outils et technologies
-
Pourquoi – Objectifs et motivation
-
Quand – Structure temporelle et planification
-
Qui – Organisation et responsabilités
Ces questions aident à définir les rôles non pas seulement par hiérarchie ou domaine fonctionnel, mais par leur responsabilité fonctionnelle dans l’espace architectural.
En Lien avec les Questions Fondamentales
Rôles/Responsabilités pour le « QUOI »
La question du « Quoi » se réfère aux objets d’information centraux d’une organisation.
Responsabilités typiques :
-
Définition des objets d’information centraux
-
Modèles de données et structures d’information
-
Qualité des données et responsabilité des données
Rôles typiques :
-
Data Architect
-
Information Architect
-
Data Owner
-
Data Steward
Ces rôles assurent que les structures de données sont cohérentes et compréhensibles à l’échelle de l’organisation.
Rôles/Responsabilités pour le « COMMENT »
Le « Comment » décrit les processus et fonctions par lesquels une organisation fournit ses services.
Responsabilités typiques :
-
Modélisation des processus métier
-
Définition des capacités (Capabilities)
-
Coordination entre le métier et l’IT
Rôles typiques :
-
Business Architect
-
Process Owner
-
Capability Manager
Ces rôles veillent à l’alignement des processus métier et des systèmes informatiques.
Rôles/Responsabilités pour le « AVEC QUOI »
La question « Avec Quoi » concerne les moyens technologiques pour la mise en œuvre des processus.
Responsabilités typiques :
-
Standards technologiques
-
Architectures de plateformes
-
Stratégies d’infrastructure
Rôles typiques :
-
Technology Architect
-
Infrastructure Architect
-
Platform Architect
Ils définissent le cadre technique dans lequel les solutions sont créées.
En Lien avec les Questions Fondamentales
Rôles/Responsabilités pour le « POURQUOI »
Le « Pourquoi » relie l’architecture à l’orientation stratégique de l’entreprise.
Responsabilités typiques :
-
Déclinaison des principes d’architecture
-
Images cibles stratégiques
-
Feuilles de route de transformation
Rôles typiques :
-
Enterprise Architect
-
Strategy Architect
-
Transformation Lead
Ces rôles assurent que les décisions d’architecture sont justifiées stratégiquement.
Rôles/Responsabilités pour le « QUAND »
Le « Quand » concerne la coordination temporelle des changements d’architecture.
Responsabilités typiques :
-
Planification de la transformation
-
Feuilles de route
-
Planification des versions et des programmes
Rôles typiques :
-
Portfolio Manager
-
Program Manager
-
Transformation Manager
Ils veillent à ce que l’architecture ne soit pas seulement conçue, mais aussi mise en œuvre dans les temps.
Rôles/Responsabilités pour le « QUI »
La question « Qui » concerne l’ancrage organisationnel du travail d’architecture.
Responsabilités typiques :
-
Structures de gouvernance
-
Rôles et responsabilités
-
Processus de décision
Rôles typiques :
-
Architecture Board
-
Domain Leads
-
Architecture Governance Lead
Ces rôles assurent que les décisions d’architecture sont institutionnellement ancrées.
Mise à l’Échelle du Concept de Rôles
Toutes les organisations n’ont pas besoin des mêmes rôles.
Le nombre et la spécialisation des rôles dépendent fortement de la taille et de la complexité de l’organisation.
Le DPBoK (Digital Practitioner Body of Knowledge) décrit quatre niveaux de contexte, sur la base desquels les rôles peuvent être mis à l’échelle de manière pertinente.
Contexte I : Individu / Fondateur
Dans les très petites organisations, une seule personne assume souvent plusieurs rôles simultanément.
Situation typique :
-
Fondateur = Stratégie, Architecture et Mise en œuvre
-
Faible séparation formelle des rôles
Caractéristiques :
-
Architecture implicite
-
Décisions rapides
-
Gouvernance minimale
Le travail d’architecture y est plutôt intuitif.
Contexte II : Équipe
Avec la croissance, les premiers rôles fonctionnels émergent.
Rôles typiques :
-
Product Owner
-
Lead Developer
-
Solution Architect
L’architecture émerge souvent au sein d’une équipe et est fortement façonnée par des produits concrets.
Contexte III : Équipe d’Équipes
À partir de ce stade, des rôles d’architecture de coordination apparaissent.
Rôles typiques :
-
Enterprise Architect
-
Domain Architect
-
Architecture Board
Tâches centrales :
-
Coordination entre les équipes
-
Principes d’architecture communs
-
Standards de plateformes et de données
L’architecture est ici pour la première fois coordonnée à l’échelle de l’entreprise.
Contexte IV : Entreprise Établie
Dans les organisations établies, l’architecture devient une fonction organisationnelle à part entière.
Structures typiques :
-
Architecture Office
-
Enterprise Architecture Practice
-
Architecture Governance
Les caractéristiques incluent :
-
Rôles clairement définis
-
Gouvernance formelle
-
Planification de transformation à long terme
Ici, l’architecture devient un instrument central de pilotage de l’entreprise.
Conclusion
Les rôles dans la Gestion de l’Architecture d’Entreprise peuvent être définis de différentes manières. Alors que des cadres comme TOGAF proposent des rôles concrets, le cadre Zachman met surtout en lumière différentes perspectives sur l’architecture.
Une dérivation systématique des rôles réussit lorsque l’architecture est structurée autour de questions fondamentales – par exemple, via les six perspectives :
-
Quoi
-
Comment
-
Avec Quoi
-
Pourquoi
-
Quand
-
Qui
Ces questions rendent visibles quelles responsabilités existent réellement dans l’espace architectural.
Quels rôles sont effectivement mis en place dépend cependant fortement du contexte organisationnel. Grâce aux niveaux de mise à l’échelle du DPBoK, il est possible de retracer comment les rôles d’architecture peuvent évoluer, d’une seule personne jusqu’à une organisation d’architecture institutionnalisée.
Cela met en évidence :
Les rôles EAM ne sont pas un ensemble rigide de titres, mais un concept organisationnel évolutif pour la responsabilité architecturale.
Once-Only dans la documentation
Once-Only dans la documentation : comment le Documentation Engineering et le Docs-as-Code mettent en œuvre ce principe
Qu’est-ce que le principe Once-Only ?
Le principe Once-Only stipule : les données ou informations ne doivent être saisies, stockées et maintenues qu’une seule fois – et réutilisées à tous les endroits pertinents. Il évite la redondance, minimise les sources d’erreurs et réduit la charge de maintenance. Initialement connu dans l’administration publique et l’e-gouvernement, il gagne une importance croissante dans la documentation technique – en particulier dans les systèmes complexes, agiles et évolutifs.
Pourquoi le Once-Only est-il important dans la documentation ?
Dans les projets logiciels, la documentation se développe souvent de manière non coordonnée :
- La documentation API existe séparément des manuels utilisateur.
- Les diagrammes sont dessinés manuellement et ne sont pas synchronisés avec le code.
- Les notes de configuration sont dupliquées dans plusieurs documents.
Cela entraîne des incohérences, des contenus obsolètes et une charge de maintenance accrue. Le Once-Only apporte ici de la clarté :
Écrire une fois. Utiliser partout.
Documentation Engineering : la base du Once-Only
Le Documentation Engineering est l’approche systématique et ingénieriale de la documentation – axée sur la structure, la réutilisabilité et l’automatisation. Il permet :
- Des documents modulaires : le contenu est décomposé en blocs réutilisables (par exemple, « descriptions de composants », « codes d’erreur »).
- Des sources centrales : tout le contenu provient d’une source unique et maintenue (Single Source of Truth).
- Une liaison automatisée : le contenu est dynamiquement traduit dans différents formats de sortie (PDF, web, systèmes d’aide).
Exemple : Un point de terminaison API est décrit dans un fichier YAML. Celui-ci sert de source pour :
- La documentation Swagger/OpenAPI
- Les sections du manuel utilisateur
- La référence développeur
- Les tests automatisés
→ Aucune copie manuelle. Aucune incohérence. Une seule source.
Docs-as-Ecosystem : la documentation comme système vivant
Un Docs-as-Ecosystem considère la documentation non pas comme un artefact statique, mais comme un système intégré et dynamique, connecté au code, aux tests, au CI/CD et à la surveillance.
Caractéristiques d’un Docs-as-Ecosystem :
- Génération automatique : la documentation est générée à partir des commentaires du code, des fichiers de configuration ou des tests.
- Boucles de rétroaction : les utilisateurs peuvent donner leur avis directement depuis la documentation – par exemple via des boutons « Cette information était-elle utile ? ».
- Gestion des versions : la documentation est versionnée avec le code – aucune discrépance entre la version 1.2 et sa documentation correspondante.
- Recherchabilité et navigation : les contenus sont liés via des moteurs de recherche et une navigation intelligente – pas seulement lisibles de manière linéaire.
Impact sur le Once-Only : Chaque contenu fait partie d’un réseau. Les modifications à un endroit se répercutent automatiquement sur tous les documents dépendants – sans maintenance manuelle supplémentaire.
Diagrams-as-Code : les visualisations sous forme de code
Les diagrammes sont souvent la plus grande source de redondance :
- Un diagramme d’architecture est créé dans PowerPoint, puis inséré dans Confluence, puis copié dans un PDF.
- Lors des modifications, il doit être mis à jour manuellement partout.
Solution : Diagrams-as-Code
Avec des outils comme Mermaid, PlantUML, Graphviz ou Diagrams.net (avec export de code), les diagrammes sont définis sous forme de texte – et peuvent être intégrés à la documentation.
Exemple (Mermaid) :
graph TD
A[Utilisateur] --> B[Passerelle API]
B --> C[Service d'authentification]
B --> D[Service de commandes]
C --> E[Base de données]
D --> E
→ Ce code peut être intégré dans Markdown, Sphinx, Docusaurus ou d’autres systèmes. → Les modifications du code mettent automatiquement à jour le diagramme dans tous les documents. → Aucune maintenance manuelle. Aucun graphique obsolète.
Docs-as-Code : la mise en œuvre technique du Once-Only
Le Docs-as-Code est la pratique qui consiste à traiter la documentation comme du logiciel :
- Versionné dans Git
- Automatisé avec CI/CD
- Validé par des tests
- Maintenu via des Pull Requests
Éléments clés :
- Dépôts de code source : la documentation réside dans le même dépôt que le code – ou dans un dépôt dédié mais lié.
- Constructions automatisées : à chaque modification, la documentation est régénérée et publiée.
- Validation : les liens sont vérifiés, la syntaxe est validée, les diagrammes sont rendus.
- Réutilisation : grâce à des mécanismes d’inclusion ou d’importation, les blocs de construction sont réutilisés dans plusieurs documents.
Exemple avec Antora (AsciiDoc) :
.. include::requirements.adoc
Les modifications apportées à requirements.adoc affectent tous les documents qui l’incluent.
Mise en œuvre pratique : étape par étape
-
Identifier les contenus redondants → Quelles sections sont copiées plusieurs fois ? Quels diagrammes existent en plusieurs versions ?
-
Créer des sources centrales → Regrouper les contenus récurrents dans des fichiers réutilisables (par exemple,
shared/,components/). -
Choisir des outils prenant en charge Docs-as-Code et Diagrams-as-Code → Markdown + Mermaid (ou AsciiDoc + PlantUML) + Git + CI/CD (par exemple, GitHub Actions, GitLab CI).
-
Intégrer la documentation dans le processus de développement → Toute modification de code affectant l’API nécessite une modification de la documentation – dans le cadre de la Pull Request.
-
Automatiser la validation et la publication → Vérifier les liens, la syntaxe, les diagrammes. Publier automatiquement sur un site de documentation.
-
Mettre en place des mécanismes de rétroaction → Les utilisateurs peuvent donner leur avis directement depuis la documentation – par exemple via des GitHub Issues ou des formulaires intégrés.
Conclusion : le Once-Only n’est pas un luxe – c’est une nécessité
Dans un monde où le logiciel est en constante évolution et expansion, la documentation manuelle n’est plus viable. Le Once-Only est la réponse :
- Efficacité : moins de travail, moins d’erreurs.
- Cohérence : tous les utilisateurs voient le même état à jour.
- Évolutivité : la documentation grandit avec le système – sans effort supplémentaire.
Avec le Documentation Engineering, le Docs-as-Ecosystem et le Docs-as-Code, le Once-Only devient non seulement possible – il devient le fondement d’une documentation moderne et vivante.
Différentes normes de modélisation de flux de données
Flux de données ou flux d’informations ?
Le flux de données décrit le transfert de données brutes et non traitées, indépendamment de leur signification métier.
Le flux d’informations, en revanche, concerne le transfert de données traitées ou interprétées, qui ont une utilité claire et identifiable pour le destinataire.
Naturellement, dans un environnement informatique, lorsque des informations doivent être transférées, cela se fait sur la base d’un transfert de données. Le flux de données constitue la base technique du flux d’informations.
Les formes de représentation décrites dans cet article utilisent des éléments des deux variantes, mais l’objectif du flux d’informations reste au premier plan.
L’exemple utilisé
Notre exemple est un envoi de factures via EDI. Le département « Comptabilité » envoie des factures au format XML via un middleware central à plusieurs clients (trois dans ce cas).
Les paramètres supplémentaires suivants sont connus :
| Paramètre | Valeur |
|---|---|
| Source des données | CRM du Marketing (pour les données d’adresse) ERP des Ventes (pour les données de facturation) |
| Émetteur | Département Comptabilité |
| Système source | Module financier |
| Destinataire | Client |
| Objet métier | Facture mensuelle |
| Objet de données | Fichier PDF |
| Technologie d’envoi | SFTP |
| Intervalle | Mensuel |
flowchart LR
CRM[CRM]
VM[ERP]
FM[Module financier]
R(Facture)
MW{Middleware}
FTP{SFTP}
K[Client]
CRM --> FM
VM --> FM
FM --> R --> MW
MW --> FTP
FTP --> K
Bien que cette interaction puisse être représentée assez simplement par un organigramme de base, certaines informations manquent. Ou plutôt, elles ne peuvent pas être facilement affichées de manière claire. Les différents niveaux (métier, application, infrastructure) ne sont pas clairement différenciés, et l’aspect temporel (mensuel) est également absent.
Différentes normes de modélisation
Plusieurs normes permettent de soutenir la modélisation des flux d’informations.
ArchiMate
En tant que langage de modélisation pour les architectures d’entreprise, ArchiMate est très bien adapté pour représenter les flux d’informations. Grâce à sa stratégie par couches, la transition du flux de données au flux d’informations peut également être illustrée.

Avantages
- Grâce aux couches d’architecture, le flux d’informations, le flux de données et l’infrastructure requise peuvent être représentés.
- Selon l’outil utilisé, les éléments individuels peuvent être liés à des entrées de portefeuille ou générés à partir d’elles.
Inconvénients
- ArchiMate est exclusivement lisible par l’homme, pas par la machine.
- Ceux qui ne connaissent pas la syntaxe ArchiMate peuvent avoir du mal à l’interpréter.
- Sans directives de modélisation claires, les modèles peuvent sembler plutôt chaotiques ; on peut se perdre dans les détails potentiels.
- Il n’existe pas d’éléments spécifiques pour les aspects temporels ; ceux-ci doivent être ajoutés sous forme de descriptions via des notes.
UML
L’UML ne possède pas son propre type de diagramme pour les flux d’informations, mais plusieurs types de diagrammes appropriés se trouvent dans le groupe des diagrammes de comportement. Pour cet article, nous appliquons le diagramme de séquence.
sequenceDiagram participant Marketing as Département Marketing participant CRM as Système CRM participant Ventes as Département des Ventes participant ERP as Système ERP participant Finance as Module financier participant MW as Middleware participant FTP as FTP Client participant Client Note over Finance: Déclencheur le 1er du mois Marketing->>CRM: Maintenance des données d'adresse Ventes->>ERP: Maintenance des données produit Finance->>CRM: Demande de données d'adresse CRM-->>Finance: Données d'adresse Finance->>ERP: Demande de données produit ERP-->>Finance: Données produit Finance->>Finance: Générer la facture mensuelle Finance->>Finance: Générer la facture PDF Finance->>MW: Transmettre la facture PDF MW->>FTP: Stocker le fichier PDF Client->>FTP: Récupérer la facture PDF
Avantages
- Représentation très structurée ; les participants sont clairement visibles.
- La séquence chronologique des actions est très claire.
- Les réponses/réactions peuvent également être clairement représentées.
Inconvénients
- Peut rapidement devenir confus ; il faut se concentrer soit sur le flux d’informations, soit sur le flux de données, pas sur les deux mélangés.
BPMN
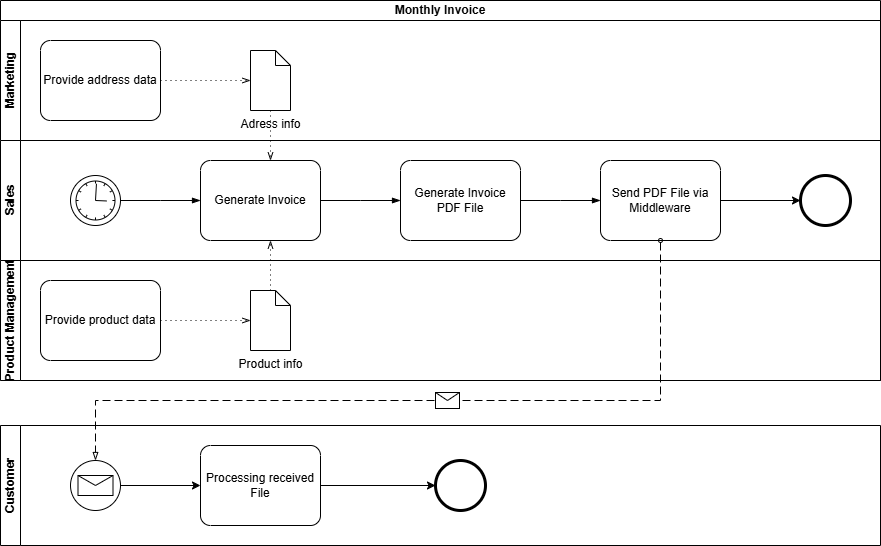
Avantages
- Grâce aux pools et aux lanes, les participants au flux d’informations peuvent être représentés de manière structurée et claire. Même des flux d’informations plus complexes avec, par exemple, plusieurs destinataires, peuvent être facilement mis en œuvre.
- Grâce aux messages d’événement, les intervalles ou les points d’exécution temporels peuvent être clairement représentés.
- Un modèle BPMN est également lisible par machine ou exécutable via un moteur BPM.
Inconvénients
- Pour représenter l’infrastructure et l’architecture entourant le flux d’informations, BPMN manque des éléments de représentation spécifiques nécessaires.
Conclusion et recommandation personnelle
Les trois notations – diagrammes de séquence UML, BPMN et ArchiMate – offrent des approches précieuses pour la modélisation des flux d’informations et des architectures. Cependant, de mon point de vue, ArchiMate se distingue : c’est le langage le plus polyvalent et particulièrement adapté pour représenter l’interaction des couches architecturales dans l’EAM – de la stratégie en passant par les processus métier jusqu’à la technologie.
ArchiMate permet de représenter non seulement les flux de séquence ou les processus (bien que pas aussi détaillés que l’UML ou le BPMN), mais surtout les dépendances et les relations architecturales. Cette vue holistique est cruciale pour comprendre et gérer des architectures d’entreprise complexes. Alors que le BPMN et les diagrammes de séquence UML sont supérieurs dans leurs domaines spécialisés – respectivement les processus et les interactions – ArchiMate offre la flexibilité nécessaire pour mapper toutes les couches avec une seule notation.
Ma recommandation :
- Pour les organisations aux ressources limitées (par exemple, les petites ou moyennes organisations), ArchiMate est le choix le plus pragmatique, car il couvre la plupart des exigences sans avoir recours à plusieurs notations.
- Si les capacités le permettent, une utilisation spécialisée des langages vaut la peine : BPMN pour la modélisation détaillée des processus, diagrammes de séquence UML pour les interactions techniques, et ArchiMate comme cadre global qui rassemble le tout.
Ainsi, ArchiMate n’est pas seulement une notation, mais un outil clé pour maîtriser la complexité des architectures d’entreprise modernes – sans perdre de vue l’ensemble.
Les portfolios dans l'EAM, faites visible avec le principe ETS
De l’ETS à l’EAM – comment les portfolios d’architecture peuvent être dérivés de questions simples
Le principe ETS (Entrée – Traitement – Sortie) décrit un modèle fondamental du traitement de l’information.
Il est volontairement simple et précisément pour cette raison universellement applicable – bien au-delà des systèmes techniques.
Lorsque ce modèle mental est transféré à la gestion de l’architecture d’entreprise (EAM), une logique étonnamment claire émerge :
Des questions directrices fondamentales peuvent être dérivées de l’ETS, qui mènent à leur tour directement aux portfolios d’architecture bien connus.
L’ETS comme point de départ
Au cœur, l’ETS décrit trois aspects :
- Entrée – quelles informations sont disponibles ?
- Traitement – qu’advient-il de ces informations ?
- Sortie – quels résultats sont produits ?
Appliqué au travail d’architecture, cela donne d’abord trois questions centrales :
- Quelles informations sont pertinentes ?
- Comment ces informations sont-elles traitées ?
- Avec quels moyens ce traitement est-il mis en œuvre ?
Ces trois questions forment le cœur substantiel de la réflexion.
Elles décrivent ce qui est examiné et comment le traitement de l’information fonctionne fondamentalement.
En pratique, cependant, il apparaît rapidement :
Cette perspective seule est insuffisante pour des décisions architecturales robustes.
L’architecture n’existe pas isolément, mais plutôt :
- au sein des organisations,
- avec un objectif spécifique,
- et sur une période prolongée.
Par conséquent, les trois questions de base doivent être complétées par des perspectives supplémentaires qui prennent en compte le contexte, la responsabilité et le temps.
De cet élargissement découlent trois questions directrices supplémentaires :
- Qui porte la responsabilité ?
- Pourquoi quelque chose est-il conçu d’une certaine manière ?
- Quand quelque chose est-il pertinent ou valide ?
Ensemble, ces six questions directrices forment une base complète, mais simple, pour explorer systématiquement les architectures d’entreprise.
Les questions directrices dérivées
Ainsi, six questions directrices fondamentales émergent de la pensée ETS :
1. Quelles informations sont pertinentes ?
Cette question découle directement de la perspective Entrée.
Elle constitue la base pour :
- les objets métier
- les informations
- les structures de données
- les flux de données
Portfolio attribué :
Portfolio Information / Données
2. Comment les informations sont-elles traitées ?
Cette question est dérivée du Traitement.
Elle décrit :
- les processus métier
- les règles de gestion
- les fonctions et services
- leur mise en œuvre dans les applications
Portfolio attribué :
Portfolio Métier & Applications
3. Avec quels moyens le traitement est-il mis en œuvre ?
Cette question fait également partie du Traitement, mais avec un accent sur les moyens.
Elle aborde :
- les technologies
- les plateformes
- l’infrastructure
- les standards techniques
Portfolio attribué :
Portfolio Technologie / Infrastructure
4. Qui est responsable ?
Cette question complète l’ETS par la dimension organisationnelle.
Elle clarifie :
- les rôles
- les responsabilités
- la propriété (ownership)
Portfolio attribué :
Portfolio Organisation / Capacités
5. Pourquoi quelque chose est-il conçu ainsi ?
Cette question établit le but.
Elle se rapporte à :
- les objectifs
- les principes
- les moteurs stratégiques
- l’argumentation de la valeur
Portfolio attribué :
Portfolio Stratégie / Motivation
6. Quand quelque chose est-il pertinent ?
Cette question introduit la dimension temporelle.
Elle décrit :
- la validité temporelle
- les transitions
- les dépendances
- les cycles de vie
Portfolio attribué :
Portfolio Feuille de route / Cycle de vie
Classification graphique
Le diagramme suivant montre comment les questions directrices peuvent être logiquement dérivées du principe ETS et attribuées aux portfolios respectifs :
flowchart TB
ETS["Principe ETS<br/>Entrée · Traitement · Sortie"]
Q1["Quelles informations ?"]
Q2["Comment est-ce traité ?"]
Q3["Avec quels moyens ?"]
Q4["Qui est responsable ?"]
Q5["Pourquoi est-ce fait ainsi ?"]
Q6["Quand est-ce pertinent ?"]
ETS --> Q1
ETS --> Q2
ETS --> Q3
Q1 --> P1["Portfolio Information / Données"]
Q2 --> P2["Portfolio Métier & Applications"]
Q3 --> P3["Portfolio Technologie"]
Q4 --> P4["Portfolio Organisation / Capacités"]
Q5 --> P5["Portfolio Stratégie / Motivation"]
Q6 --> P6["Portfolio Feuille de route / Cycle de vie"]
Le diagramme ne montre pas une hiérarchie, mais plutôt une dérivation conceptuelle :
- L’ETS fournit le modèle de base
- les questions directrices explorent le contexte
- les portfolios structurent le contenu
Points communs et dépendances
En pratique, ces portfolios n’existent pas isolément :
- Sans clarté sur les informations, les processus et les systèmes restent flous.
- Sans compréhension du traitement, le lien entre le métier et l’IT est absent.
- Sans technologie adaptée, les exigences ne peuvent être mises en œuvre.
- Sans responsabilité définie, le savoir n’est pas durable.
- Sans but stratégique, la légitimité manque.
- Sans référence temporelle, aucun pilotage n’est possible.
Les questions directrices agissent comme l’élément de liaison entre les portfolios.
Conclusion
Le principe ETS montre comment le traitement de l’information fonctionne fondamentalement.
En en dérivant des questions directrices simples et en les attribuant aux portfolios EAM bien connus, une structure claire et compréhensible pour le travail d’architecture émerge.
La valeur ajoutée ne réside pas dans de nouveaux cadres, mais dans l’application cohérente de questions simples :
Un bon travail d’architecture commence là où
les connexions sont comprises –
et non là où une complexité supplémentaire est créée.
Parfois, il suffit de réorganiser ce qui est déjà connu.
Principe ETS dans le contexte de l'EAM
Qu’est-ce que le principe ETS ?
Le principe ETS (en anglais IPO-model) désigne le principe fondamental du traitement des données, où les trois lettres signifient Entrée (Input), Traitement (Processing) et Sortie (Output).
Ces trois termes décrivent la logique de base du traitement de l’information.
flowchart LR
id1("Entrée") --> id2("Traitement") --> id3("Sortie")
style id1 fill:#ffff00,stroke:#333,stroke-width:2px
style id2 fill:#00ffff,stroke:#333,stroke-width:2px
style id3 fill:#ffff00,stroke:#333,stroke-width:2px
Au sens classique, cela fait référence aux composants physiques, c’est-à-dire au matériel :
| Entrée | Traitement | Sortie |
|---|---|---|
| Clavier Souris Pavé tactile Joystick Scanner Lecteur de codes-barres/QR |
Processeur principal CPU Chipset Contrôleur |
Écran Display Haut-parleurs Vidéoprojecteur Imprimante Traceur |
Cependant, le principe est beaucoup plus universel que la simple application aux composants informatiques physiques.
Où peut-il encore être appliqué ?
Le principe ETS peut être appliqué dans tous les domaines imaginables. Chaque interaction, chaque processus peut être modélisé ainsi.
Car chaque interaction, même un simple dialogue entre deux personnes, reçoit des informations, les traite et génère une réponse.
À titre d’exemple, voici un court dialogue concernant le bien-être, vu du côté de la personne interrogée :
flowchart LR
id1("Entend 'Comment ça va ?'") --> id2("Traite la question, réfléchit à la réponse") --> id3("Répond 'Très bien, merci.'")
style id1 fill:#ffff00,stroke:#333,stroke-width:2px
style id2 fill:#00ffff,stroke:#333,stroke-width:2px
style id3 fill:#ffff00,stroke:#333,stroke-width:2px
Chaque situation ou chaque processus peut être décomposé en trois étapes : Acquisition d’information, Traitement de l’information et Diffusion de l’information.
Le principe ETS dans l’EAM
Pour transposer durablement le principe ETS aux architectures d’entreprise, les éléments doivent encore être sécurisés par des questions fondamentales.
- Quoi (quelles informations sources) ai-je besoin pour démarrer ou pouvoir démarrer le processus ?
- Quoi (quelles informations cibles) ai-je besoin pour achever le processus ?
- Comment (selon quelles règles) est-ce que je transforme les informations sources en informations cibles ?
Avec ces questions, le principe ETS classique est traité. Pour les architectures, la question suivante doit impérativement être posée :
- Avec quoi (par quels moyens) est-ce que j’atteins cet objectif ?
Les questions du Quoi et du Comment sont fondamentalement traitées au niveau métier, car elles concernent principalement le processus fonctionnel.
Le Avec quoi est fourni par le niveau technique (via l’infrastructure).
Le niveau du système d’information (aussi appelé niveau applicatif) sert d’intermédiaire/traducteur et assure un soutien fluide du département métier par l’IT. Ainsi, le sens et le but des architectures d’entreprise sont remplis.
flowchart TD
id1("Architecture Métier") <--Quoi ? Comment ?--> id2("Architecture du Système d'Information") <--Avec quoi ?--> id3("Architecture Technique")
style id1 fill:#ffff00,stroke:#333,stroke-width:2px
style id2 fill:#00ffff,stroke:#333,stroke-width:2px
style id3 fill:#00ff00,stroke:#333,stroke-width:2px
Aux questions de base Quoi, Comment et Avec quoi, s’ajoutent les questions complémentaires suivantes :
- Pourquoi est-ce nécessaire ? (Sens et objectif)
- Quand (Pour quand) en a-t-on besoin ? (Délai)
- Qui en est responsable ? (Responsabilité)
Les questions complémentaires sont volontairement très générales, car elles peuvent être posées ponctuellement à n’importe quelle étape du processus.
| POURQUOI | QUAND | QUI | |
|---|---|---|---|
| QUOI | À quoi servent les informations sources/cibles ? | Quand/Dans quel délai les informations sources/cibles sont-elles nécessaires ? | Qui est responsable des informations sources/cibles ? (Data Owner) |
| COMMENT | Pourquoi les informations doivent-elles être traitées ? | Quand/Dans quel délai les informations doivent-elles être traitées ? | Qui est responsable du traitement ou du processus de traitement ? (Process Owner) |
| AVEC QUOI | Comment l’utilisation de l’outil requis est-elle justifiée ? | Quand quel outil est-il nécessaire/utilisé ? | Qui est responsable des outils requis ? |
Conclusion
Toute personne qui s’occupe depuis un certain temps de gestion de l’architecture d’entreprise (EAM) et qui a eu un aperçu d’un ou plusieurs frameworks retrouvera ces questionnements.
Le Framework Zachman connaît également six perspectives identifiées par des mots interrogatifs : Quoi (Données), Comment (Fonction), Où (Réseau), Qui (Personnes), Quand (Temps) et Pourquoi (Motivation). La seule différence dans ma représentation est que j’ai remplacé le Où par le Avec quoi. La raison en est assez simple à expliquer. Dans le monde d’aujourd’hui, nous sommes tellement numérisés et connectés que le Où physique ne joue plus qu’un rôle subordonné, voire presque plus aucun. Plus importants aujourd’hui sont les outils utilisés, c’est-à-dire le Avec quoi.
Dans ma représentation, je me suis également orienté vers TOGAF, où les questionnements ne sont pas explicitement mentionnés ainsi, mais sont couverts par les niveaux d’architecture proposés :
- Architecture Métier : Décrit les aspects “Qui” et “Pourquoi” (par ex. organigrammes, objectifs, principes).
- Architecture des Données : Se concentre sur le “Quoi” (par ex. modèles de données, flux de données).
- Architecture des Applications : Traite le “Comment” (par ex. cartographie des applications, interfaces).
- Architecture Technologique : Adresse le “Avec quoi” (par ex. infrastructure, réseaux, sites).
Ma représentation de l’ETS par rapport à l’EAM ne constitue donc pas une réinterprétation complète, mais vise plutôt à montrer, d’un point de vue pragmatique, comment cela peut être appliqué.